Chapter #1: Linux I/O Streams, Redirection, and Text Processing
In this chapter, you’ll learn how Linux handles input and output streams, and how to manipulate them using redirection, pipes, and essential text-processing commands like sed, cut, grep, and uniq.

Linux treats the input to and the output from programs as streams (or sequences) of characters.
To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
Both input to and output from commands are treated as a text stream or sequence. There are 3 types of I/O streams, each being represented by the numbers 0, 1, and 2:
- Standard Input, also known as stdin, consists of data being sent as input to a command. Usually, stdin is entered through the keyboard or is the result of a previous command. The file descriptor that is assigned to stdin is 0.
- Standard Output, or stdout, is the channel where the output of a command is returned after its execution. Usually, stdout is the computer screen, but can also be redirected to a file. The file descriptor that is assigned to stdout is 1.
- Standard Error (stderr) is the channel used by a program to return error messages (if any) resulting from its execution. Although stderr will also be returned to the screen, it is important to distinguish it from stdout to handle it properly. The file descriptor, in this case, is 2.
This separation allows error messages to be redirected separately from standard output, which can be particularly useful when troubleshooting scripts or logging errors to a file while displaying normal output to the screen.
Redirection and Pipelines
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command:
command > file1.txt
command >> file1.txt
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline.
An important distinction to keep in mind:
>overwrites a file>>appends to an existing file without erasing its contents
For example:
echo "First line" > notes.txt
echo "Second line" >> notes.txt
One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe - the stdout of the first command is not written to a file and then read by the second command.
Redirecting stderr and stdout Together
You can also redirect stderr (standard error) separately from stdout (standard output). This is useful when you want to store or discard errors independently of regular output.
Redirect error output to a file:
command 2> error.log
Redirect both stdout and stderr to the same file:
command > output.log 2>&1
Ignore errors completely:
command 2>/dev/null
Here, /dev/null is a special device file that discards everything written to it, often used to suppress unwanted messages.
For the following practice exercises, we will use the poem “A Happy Child” (anonymous author) from the file ahappychild.txt.
My house is red - a little house;
A happy child am I.
I laugh and play the whole day long,
I hardly ever cry.
I have a tree, a green, green tree,
To shade me from the sun;
And under it I often sit,
When all my play is done.
Using sed Command
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
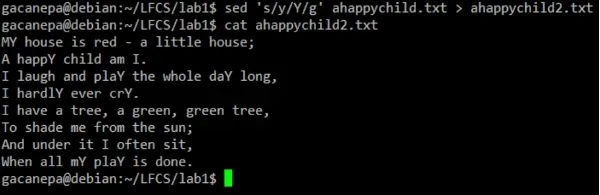
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt.
The g flag indicates that sed should perform the substitution for all instances of a term on every line of a file. If this flag is omitted, sed will replace only the first occurrence of the term on each line.
Basic syntax:
sed 's/term/replacement/flag' file
Our example:
sed 's/y/Y/g' ahappychild.txt > ahappychild2.txt
You can verify the output with cat ahappychild2.txt or use diff ahappychild.txt ahappychild2.txt to see the exact changes.
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
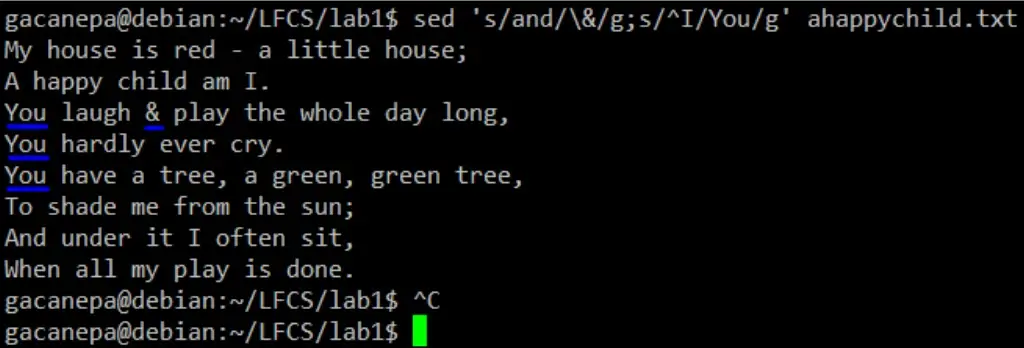
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
You can also write multi-command sed scripts in a file and run them with -f for more complex transformations.
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8:
sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
Note that by default, sed prints every line. We can override this behavior with the -n option and then tell sed to print (p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of the line in the first case and lines 1 through 5 inclusive in the second case).
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments.
The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions):
sed '/^#\|^$/d' apache2.conf
Manipulating Text Files From The Command Line
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default.
We must note that uniq does not detect repeated lines unless they are adjacent, which means you'll often need to sort the file first to bring duplicates together before using uniq.