Chapter #20: Setting Up a Caching DNS Server
Learn to configure a recursive caching DNS server on Linux, set up forward/reverse zones, MX/PTR records, and secure it with firewall rules.

Imagine what it would be like if we had to remember the IP addresses of all the websites that we use daily. Even if we had a prodigious memory, the process to browse to a website would be ridiculously slow and time-consuming.
And what about if we needed to visit multiple websites or use several applications that reside in the same machine or virtual host? That would be one of the worst headaches I can think of - not to mention the possibility that the IP address associated with a website or application can change without prior notice.
Just the very thought of it would be enough reason to desist using the Internet after a while.
That’s precisely what a world without Domain Name System (also known as DNS) would be. Fortunately, this service solves all of the issues mentioned above, even if the relationship between an IP address and a name changes.
For that reason, in this chapter, we will learn how to configure and use a caching DNS server, a service that will allow translating domain names into IP addresses and vice versa.
Introducing Name Resolution
For small networks that are not subject to frequent changes, the /etc/hosts file can be used as a rudimentary method of domain name to IP address resolution.
With a very simple syntax, this file allows us to associate a name (and/or an alias) with an IP address as follows:
[IP address] [name] [alias(es)]
For example:
192.168.0.1 gateway gateway.mydomain.com
192.168.0.2 web web.mydomain.com
Thus, you can reach a machine by its name, alias, or IP address.
For larger networks, or those that are subject to frequent changes, using the /etc/hosts file to resolve domain names into IP addresses would not be an acceptable solution. That’s where the need for a dedicated service comes in.
Under the hood, a DNS server queries a large database in the form of a tree, which starts at the root (“.”) zone.
The following image will help us to illustrate:
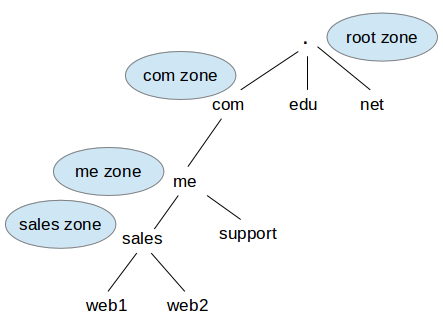
In the image above, the root (.) zone contains .com, .edu, and .net domains. Each of these domains are (or at least can be) managed by different organizations to avoid depending on a big, central one. This allows proper distribution of requests in a hierarchical way.
Let’s see what happens under the hood:
- When a client makes a query to a DNS server for
web1.sales.me.com, the server sends the query to the top (root) DNS server, which points the query to the name server in the.comzone. - This, in turn, sends the query to the next level name server (
me.com), and then tosales.me.com. This process is repeated until the FQDN (Fully Qualified Domain Name,web1.sales.me.comin this example) is returned by the name server of the zone where it belongs. - In this example, the name server in
sales.me.comresponds for the addressweb1.sales.me.comand returns the desired domain name-IP association and other information as well (if configured to do so).
All this information is sent to the original DNS server, which then passes it back to the client that requested it in the first place. To avoid repeating the same steps for future identical queries, the results of the query are stored in the DNS server.
These are the reasons why this kind of setup is commonly known as a recursive or caching DNS server.